About two years ago, some Unicode-based tricks made the news that could be used by an attacker to sneak malicious changes through code reviews. In this blog post I want to check how well the three popular Git hosting platforms GitLab, GitHub and Bitbucket handle them now. Do they warn me during a review, or do these tricks still work? On top of this I want to see how good they handle complicated diffs with moved or reformatted code, since such diffs could also be used to hide malicious code.
If you want to check how your code review tool would handle these cases, you can find all the examples in this GitHub repo. Just compare the test branch against master.
Was it fixed?
Let’s revisit the Unicode tricks mentioned in the introduction and see how well the different tools handle them.
Homoglyphs
Most modern programming languages allow you to use almost any valid Unicode letter in identifiers. This can be exploited by using characters that have a different Unicode code point but look (almost) identical. These characters are known as homoglyphs.
Let’s take a look at this Python example:
import hashlib
password = "test"
for i in range(0, 10):
pаssword = hashlib.sha256(password.encode("utf-8")).hexdigest()
print (password)
When you run the code, you will see that it prints test and that the loop has no effect. The reason for this is that password and pаssword are two different variables. The pаssword = ... inside the loop uses the Cyrillic letter а while all other occurrences use the Latin letter a. The hash is assigned to a new variable that is never used again.
I tested all three git hosters and none of them warned me about homoglyph characters. So it is not possible to detect this attack just by using their web interface.

Tip: You can use your CI pipeline to check for homoglyph characters. If you are lucky and your linter has a rule for homoglyph characters, you may just need to enable it. Otherwise you can write a simple script that searches your files for the offending characters. You can find a list of homoglyphs here or here.
Invisible characters
You know what is even more dangerous than look-alike characters? Characters that are invisible but are considered letters and therefore allowed in identifiers.
Check out this JavaScript example:
let password = "foo";
if (password =ㅤ=ㅤ= "bar") {
console.log("Access granted");
} else {
console.log("Access denied");
}
When you run this code, you will see that it always prints Access granted. Can you spot why?
If you are using a monospace font that renders the invisible character (Hangul Filler) as space, you can quite quickly see that something fishy going on (i.e. it looks like password = = = "bar"). Otherwise the illusion is perfect and it will look like password === "bar". In any case, the attack works by assigning "bar" two times to an invisible identifier and then to password instead of doing a comparison.
An attacker could also append invisible characters to variable names to create multiple look-alike variants. Another creative way of introducing a backdoor using this technique is described here.
Again, none of the tested git hosters warned me about these potentially dangerous characters.
Bidirectional text
Not all languages write their words left to right (LTR), some (e.g. Arabic) use right to left (RTL) instead. To make it possible to mix both languages on the same line, Unicode supports special characters that tell the text renderer to switch the order in which the following words are displayed. This can be used to confuse a reviewer as the order in which the code is displayed is different from what a compiler or interpreter sees. This attack is described in Trojan Source: Invisible Vulnerabilities.
Here is an example to demonstrate this:
def check_password(password, hashed_password):
"""Raise an exception if the password does not match or """;return
if some_hash(password) != hashed_password:
raise InvalidPassword()
Can you spot it? You may notice that the return is highlighted incorrectly and that your browser behaves strangely when you try to select the line. If we replace the RLI character, which reverses the word order, with [RLI] as a placeholder, you can see what is really going on:
"""Raise an exception if the password does not match or [RLI]""";return
This attack has received quite a bit of attention when it was published and all tested tools can detect it. The way they inform the user is quite different though.
GitHub provides an explanation of the attack, including a button to let you toggle between both visual representations. GitLab on the other hand adds only a single character to indicate the potential issue and displays the code always using the potentially dangerous representation. Unless you hover over the special character you may think it is just an unsupported character of your font. Bitbucket replaces the character with a placeholder containing the Unicode point, showing you the code how a compiler would see it.



Complicated diffs
So far we have been testing how the tools protect us against Unicode tricks. Sometimes, though, you don’t have to think so complex. Burying a malicious code change in a complex diff can be enough to practically hide it from a reviewer. In this section I want to see how well the tools help us spot the relevant changes when code gets moved or reformatted.
Moved code
Moving code around is sometimes a necessary step when refactoring a class or function. But if the tools rely on the developer to manually compare the new and old code, it is also a great way to hide small changes. It is simply unlikely that a developer will tediously compare each line by hand.
Let’s use this as an example and see if any of the tools can help us find the changed operator:
+def validate_user(user, password):
+ if user.password != hash_password(password) or user.disabled or user.expired is now():
+ raise LoginDenied()
+
+
def login_user(db, username, password):
user = get_user_by_name(db, username)
- if user.password != hash_password(password) or user.disabled or user.expired <= now():
- raise LoginDenied()
+ validate_user(user, password)
None of the git hosters supported me in reviewing the moved block of code. They just treat the code as added and deleted. So it is up to the reviewer to carefully check if the moved code contains additional changes.
Reformatted code
Another type of change that can be difficult to review is reformatted code. If small changes to the code style are enough to break the mapping between the old and new code in the diff, an attacker could use this to hide even large changes. The reviewer would have to go the extra mile of manually running a formatter on the old code and then comparing the output against the submitted code to detect these changes.
Let’s reuse the last example and reformat it slightly:
def login_user(db, username, password):
user = get_user_by_name(db, username)
- if user.password != hash_password(password) or user.disabled or user.expired <= now():
+ if (
+ user.password != hash_password(password)
+ or user.disabled
+ or user.expired >= now()
+ ):
raise LoginDenied()
user.last_login = now()
Since all tools compare the code using its textual representation, they are naturally limited in how they can help us. That doesn’t mean there is no difference between them. GitHub/GitLab work purely line based which means they can’t provide a useful diff when line breaks are added or deleted. Bitbucket offers a word based diff mode that doesn’t have this limitation. This makes it much easier to spot the changed operator, as you can see below.


Bonus: Evil Merge
Since we are already discussing ways to hide changes in pull requests, I wanted to mention another trick that is unrelated to diffs but that some reviewers may be unaware of. Here is how it works:
An attacker creates their feature branch and makes a commit. As next step they merge the master or main branch back into their feature branch, ideally with some merge conflicts. During merge conflict resolution they introduce their malicious changes. After that they add one or more commits, so it looks something like this:
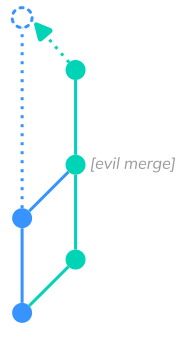
If the pull request is large, the reviewer may try to reduce their workload by going through it commit by commit instead of checking the entire diff. Unless the reviewer also properly verifies the merge commit, the malicious changes will go unnoticed because they are not part of any normal commit.
Tip: Either completely disallow merges into feature branches (i.e. use a rebase workflow instead) or make sure you review merge commits as well.
Conclusion
To get a better overview of the results, I summarized them in a table:
| Platform | GitHub | GitLab | Bitbucket |
|---|---|---|---|
| Homoglyphs | ❌️ | ❌️ | ❌️ |
| Invisible characters | ❌️ | ❌️ | ❌️ |
| Bidirectional text | ✅️ | ✅️ | ✅️ |
| Moved code | ❌️ | ❌️ | ❌️ |
| Reformatting code | ❌️ | ❌️ | ✅️ |
I was a bit surprised that all tested git hosters could only detect one of the Unicode based attacks. Many code editors do a much better job of warning the user about them. Their handling of complex diffs also leaves a lot to be desired. Adding line breaks was already enough to break the code matching in GitLab and GitHub. Only Bitbucket offered a word-based diff mode that was able to highlight changes within reformatted code.
While the platforms don’t detect all the Unicode attacks, it is relatively easy to defend your codebase against them. Run a script in your CI to scan for these special characters and deny merging if any are found. However, if you want to get a better diff, you will have to resort to external tools.
If you use GitHub, you may want to try our SemanticDiff GitHub App. It is an alternative review tool for pull requests. SemanticDiff parses your code to filter out irrelevant changes, such as added optional commas or unnecessary parentheses, and provides helpful annotations for refactored code. Click here to see how it handles the tests from this blog post.